json-size-explorer helps you discover where JSON document size goes
July 08, 2018
When trying to improve the performance of an application, one rule is to do less. When working with JSON documents, doing less means to reduce their size. By being smaller, they faster to serialize, faster to deserialize. They take less memory, less time to be transferred.
Sadly, reducing the size means changing the structure, which means also changing the consumer of the document. For example, you reduce the length of the different keys you are using, or try to reduce duplication.
But how do you know what is duplicated? How do you know which key to rename, and what would the potential win? To answer this question, I wrote a small CLI tool: json-size-explorer.
By feeding him a JSON file, it will print a bunch of statistic about it:
- number of keys
- size taken by the keys
- most frequent key
- key taking the most space
- most frequent value
- biggest value
- duplicates
The current results are kind of ugly:
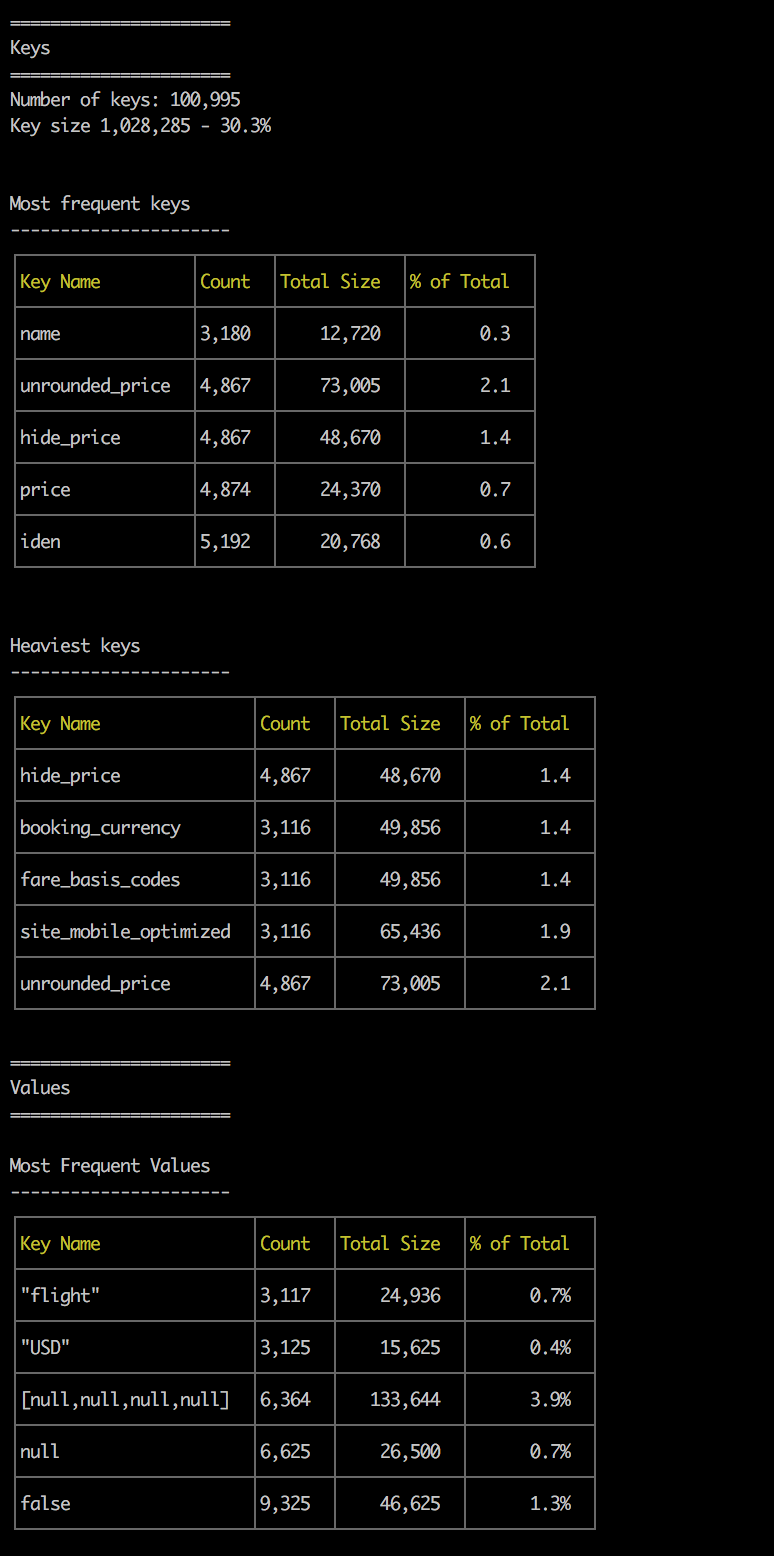
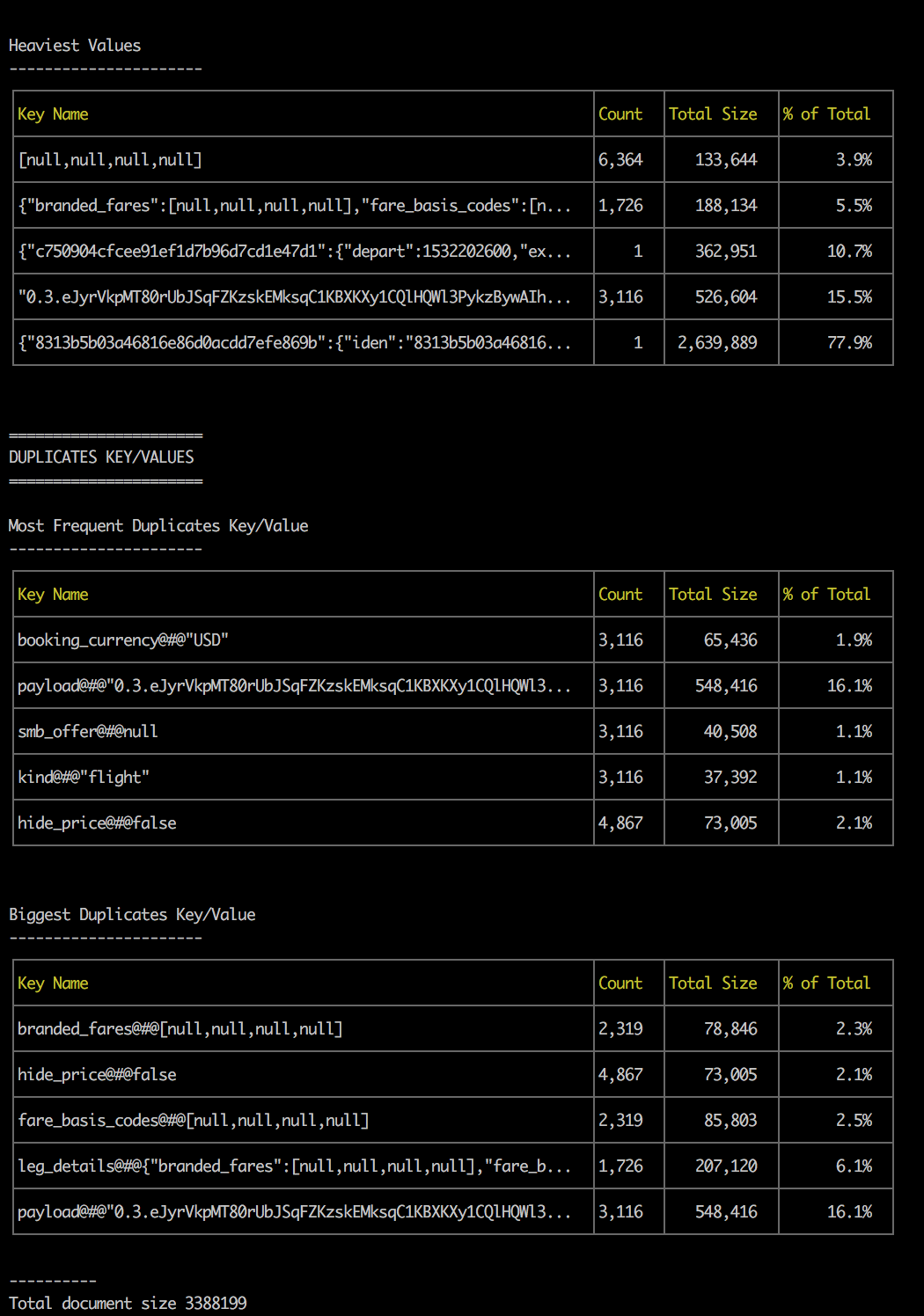
But you can see that for this 3+mb file, more than 30% of it are just keys and one specific key/value is repeated 3,116 times, taking more than 16% of the total file size.
Pull requests are welcome.